
SQL优化,算是数据库优化的一个子集。
因此,吹大牛的候选人简历上,会赫然写着”擅长MySQL数据库优化“,而吹小牛的候选人简历上,往往会写”擅长SQL优化“。
但结局是殊途同归的,就是当问他们用什么方式做的优化,他们都会说上三个字:”加索引“。
当然,好一点儿的会说可以加联合索引,它有最左前缀匹配原则(8.0以后的版本就不完全对了)之类的,还能说说覆盖索引。
那么,我的这篇文章,就好好聊聊这个面试话题。
先教大家一个小窍门,最好大家在回答面试官这个问题的时候,最好可以做到跟自己简历中项目的进行真实场景带入,这样会给面试官一种可以理论结合实践的感觉,是个大大的加分项。
举个例子,话术为:
“当时我负责电商平台的商品中心优化,我发现在展示商品列表的时候,一旦深分页就会出现加载缓慢的问题,然后我就看了一下对应的SQL语句,是这样写的:
select id, name, status, detail from product limit 10, 30;
那么一旦在深分页的话,SQL语句就会变成这样:
select id, name, status, detail from product limit 100000, 30;那么MySQL的执行方式为:一共需要查100030条数据,然后丢弃前面的100000条,只返回后面的30条数据,这样做是非常浪费资源的。
于是我把SQL改为:
select id, name, status, detail from product where id > 100000 limit 30;
100000为上次分页中最大的商品ID,先找到它,然后再根据主键ID扫描后续30条数据。
这样做性能很高,把SQL语句从原先的耗时4300ms,降低到了18ms。”
好了,下面我正式给大家列举一下,SQL优化的N种技巧,select * 这种的就不写了哈。
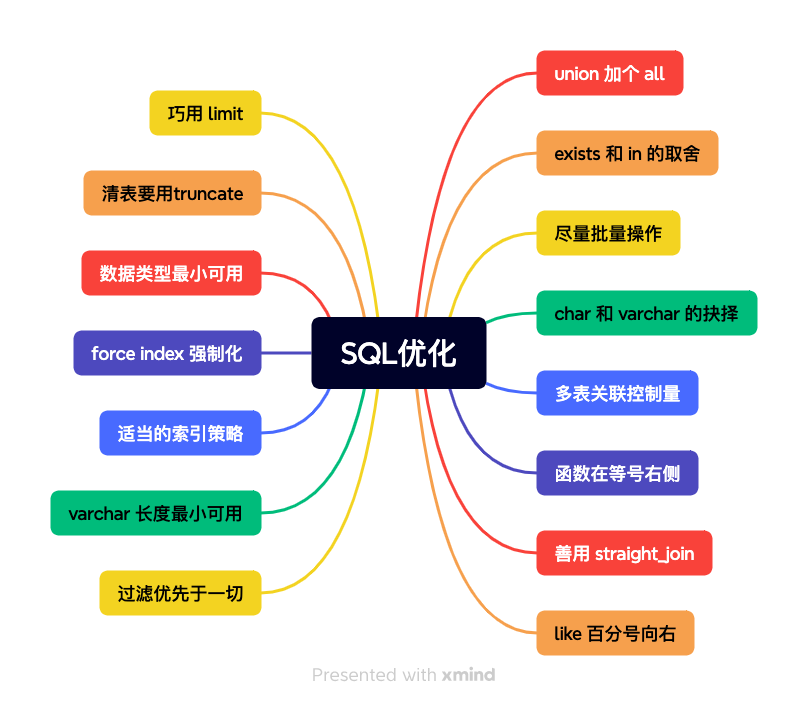
上文已经讲解了,仔细看下即可。
反例:
select * from employee where address like '%通州区%';
select * from employee where address like '%通州区';正解:
select * from employee where address like '%北京市通州区';原因:
(1)全模糊查询,或者左边出现%的模糊查询,会导致索引实效,应该尽量从查询方式或表结构设计上避免。
(2)若无法避免,且数据量庞大的情况下,一定要使用ElasticSearch进行替代。
反例:
select product_id from orders where id=100
union
select product_id from orders where id=200;
正解:
select product_id from orders where id=100
union all
select product_id from orders where id=200;原因:
union:对两个结果集进行并集操作,不包括重复行,相当于distinct,同时进行默认规则的排序;
union all:对两个结果集进行并集操作,包括重复行,不进行排序;
union因为要进行重复值扫描,所以在结果集庞大的情况下,效率极低,因此建议使用union all。
若结果集去重是强需求,则在应用程序代码上进行去重,因为数据库资源要比应用服务器资源更加珍贵。
straight_join功能同inner join类似,但能让左边的表来驱动右边的表,通过改变优化器对于联表查询的执行顺序的方式,获取更好的性能。
btw:若驱动表(左边)的数据量小于(被驱动表),它的执行性能要高于,驱动表(左边)的数据量大于(被驱动表)。
举个例子:
select * from t2 straight_join t1 on t2.a=t1.a;比如上面这个,如果我们事先知道t2表的数据量一定小于t1表的话,就可以使用上面的方式指定t2表为驱动表。
需要注意的点:
(1)straight_join只适用于inner join,并不适用于left join,right join。
(2)大部分情况下,MySQL优化器是可以做出正解的。因此,使用straight_join一定要慎重,因为部分情况下人为指定的执行顺序并不一定会比优化引擎要靠谱。
select * from student where school_id in (select id from school);
select * from police p where exists (select 1 from user u where u.id=p.id);如果子查询得出的结果集数据较少,主查询中的表较大且又有索引时,应该用in;反之,如果外层的主查询数据较少,子查询中的表大,又有索引时使用exists。
in 是把外表和内表作 hash 连接,而 exists 是对外表作 loop 循环,每次 loop 循环再对内表进行查询。所以,我们会以驱动表的快速返回为目标,目标是以小表驱动大表,这是性能优化的本质。
之前有一种比较扯淡的说法,“exists 比 in 效率高”,大家试想一下,如何一个事物在任何场景下,都优于另外一个事物,那另外一个事物就没有存在的必要性了。
反例:
delete from user;正解:
truncate user;原因:
(1)truncate是直接把表删除,然后再重建表结构,性能很高,但删除操作记录不记入日志,不能回滚。
delete语句执行删除的过程是每次从表中删除一行,性能较低,但该行的删除操作会作为事务记录在日志中保存,以便进行进行回滚操作。
(2)truncate后,表和索引所占用的空间会恢复到初始大小,而delete只是将被删除的记录标记为已删除,不会立即减少表或索引所占用的空间。
反例:
insert into student(name, sex, age) values('Tom', 1, 20);
insert into student(name, sex, age) values('Tony', 1, 18);正解:
insert into student(name, sex, age) values('Tom', 1, 20), ('Tony', 1, 18);原因:
SQL批量操作,即一次数据库操作中插入多个数据行,相比于单条插入,可减少大量的IO交互和SQL解析开销,从而提高了插入效率。
反例
select city, avg(area) from country group by city having city='beijing' or city='shanghai';
正解:
select city, avg(area) from country where city='beijing' or city='shanghai' group by city;原因:
记住,无论是分组还是排序,或者多表join,如果可以的话,第一件事就是把用不到的记录先过滤掉。
反例:
select * from article where left(title, 4)='环球资讯';
正解:
select * from article where title=left('环球资讯', 4);
原因:
如果在索引列上使用函数,会导致索引实效。
一般情况下,应该尽量使用可以正确存储数据的最小数据类型。更小的数据类型通常会使SQL执行更快,因为它们占用更少的磁盘、内存和CPU缓存,并且处理时需要的CPU周期也更少。
但是,要确保没有低估需要存储的值的范围,因为在表schema中修改数据类型是一件非常耗时和痛苦的操作(特指表数据量很大的场景)。如果无法确定哪个数据类型是最好的,就选择你认为不会超过范围的最小类型。
举个例子:如果确定只需要存0—200,tinyint unsigned类型是最适合的。
char:定长,存取效率高,一般用于固定长度的表单提交数据存储,例如:身份证号,手机号,电话,密码等,长度不够的时候,会采取右补空格的方式。
varchar:不定长,更节省空间,需要用一个或者两个字节来存储数据的长度。具体规则是:如果列的最大长度小于或等于255字节,则只使用1个字节表示,否则使用2个字节。
varchar由于行是变长的,在UPDATE时可能使行变得比原来更长,会导致分裂页和产生碎片。
有人认为,既然varchar是变长的,那我就尽量给它设置得大一些,以备不时之需,反正没有坏处。
其实,varchar(5) 和 varchar(200)是不一样的!
我们看下《高性能MySQL》一书中的原话:

因此,当你把varchar的长度调整为最小可用,是可以帮助你优化SQL排序性能的。
适当的索引策略,经过业务取舍后,可以使SQL执行得更快。
MySQL查询优化器在执行SQL语句时,会选择它认为最合适的索引,但有时却并不准确,不是实际上最快的索引,此时可以用force index人为指定索引。
force index 跟着表名后面,用于强制使用指定的索引名(key)。
如下列所示:
select * from msg force index(idx_dest_src) where dest='18736809673' and src in ('15144804019', '18674654894');据说,阿里巴巴开发者手册规定,join表的数量不应该超过3个,这个我还真没看到。
我个人觉得,多表关联需要控制量,但没必要完全一杆子拍死。
如果某个系统中,有很多多表关联的大SQL,那确实意味着表结构设计有问题,或者需要引入ES等技术方案了。
整体就这么多,后续如果有新的,我再补充。
最后,再给知友们来一波福利。
本人在之前看机会的时候,也从网上找遍了各式各类的八股文资料,但总觉得答案还不够准确,深度还有所欠缺,或是内容组织的逻辑性还不够清晰。
于是,我便自己动手,丰衣足食地自己总结了一套博采众家之长的八股文,那可真是字字斟酌,题题验证。
现在,我“大公无私”地把它分享出来,希望更多的同学可以由此受益。
Java技术栈的经典八股文最后,祝大家工作顺利,纵情向前,人人都能收获自己满意的offer。
SQL优化是提高数据库查询性能和效率的重要手段。下面列举了一些常用的SQL优化方式:
SELECT *,而是只选择需要的列。这些方法并非孤立的,通常需要综合考虑和实践。不同的数据库系统可能会有特定的优化技巧和最佳实践,因此需要根据实际情况进行调整和优化。
MySQL性能调优,90%的情况是在优化sql语句。
sql优化是一个大家都比较关注的热门话题,无论你在面试,还是工作中,都很有可能会遇到。
如果某天你负责的某个线上接口,出现了性能问题,需要做优化。那么你首先想到的很有可能是优化sql语句,因为它的改造成本相对于代码来说也要小得多。
最近无意间获得一份BAT大厂大佬写的刷题笔记,一下子打通了我的任督二脉,越来越觉得算法没有想象中那么难了。
[BAT大佬写的刷题笔记,让我offer拿到手软](这位BAT大佬写的Leetcode刷题笔记,让我offer拿到手软)
那么,如何优化sql语句呢?
这篇文章从15个方面,分享了sql优化的一些小技巧,希望对你有所帮助。
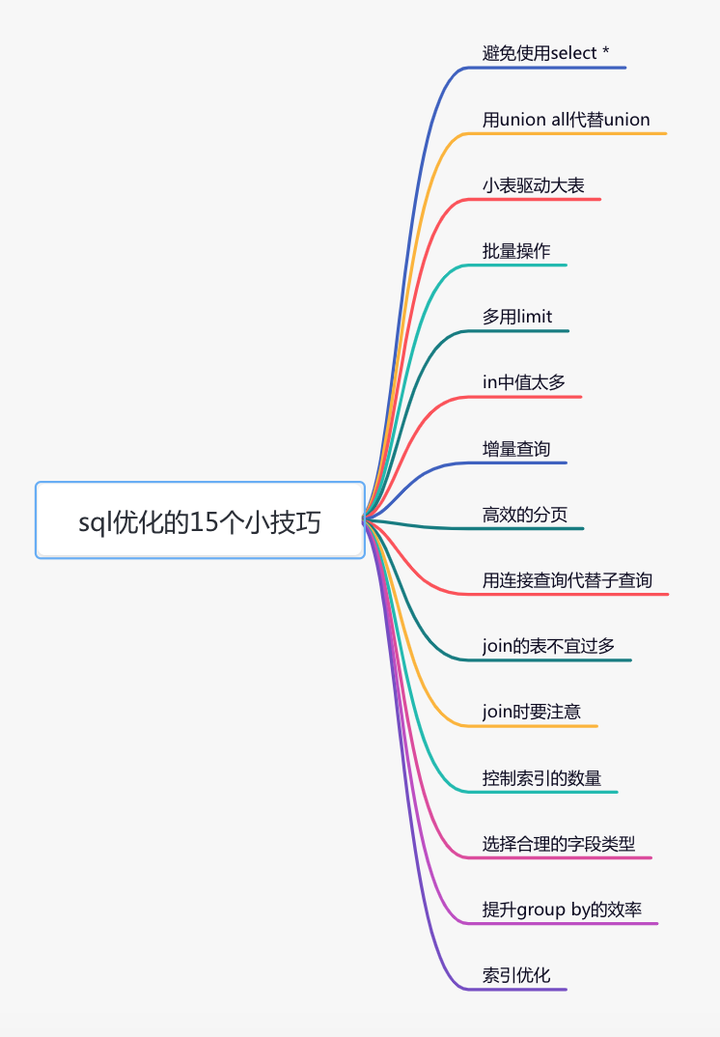
很多时候,我们写sql语句时,为了方便,喜欢直接使用select *,一次性查出表中所有列的数据。
反例:
select * from user where id=1;在实际业务场景中,可能我们真正需要使用的只有其中一两列。查了很多数据,但是不用,白白浪费了数据库资源,比如:内存或者cpu。
此外,多查出来的数据,通过网络IO传输的过程中,也会增加数据传输的时间。
还有一个最重要的问题是:select *不会走覆盖索引,会出现大量的回表操作,而从导致查询sql的性能很低。
那么,如何优化呢?
正例:
select name,age from user where id=1;sql语句查询时,只查需要用到的列,多余的列根本无需查出来。
我们都知道sql语句使用union关键字后,可以获取排重后的数据。
而如果使用union all关键字,可以获取所有数据,包含重复的数据。
反例:
(select * from user where id=1)
union
(select * from user where id=2);排重的过程需要遍历、排序和比较,它更耗时,更消耗cpu资源。
所以如果能用union all的时候,尽量不用union。
正例:
(select * from user where id=1)
union all
(select * from user where id=2);除非是有些特殊的场景,比如union all之后,结果集中出现了重复数据,而业务场景中是不允许产生重复数据的,这时可以使用union。
小表驱动大表,也就是说用小表的数据集驱动大表的数据集。
假如有order和user两张表,其中order表有10000条数据,而user表有100条数据。
这时如果想查一下,所有有效的用户下过的订单列表。
可以使用in关键字实现:
select * from order
where user_id in (select id from user where status=1)也可以使用exists关键字实现:
select * from order
where exists (select 1 from user where order.user_id=user.id and status=1)前面提到的这种业务场景,使用in关键字去实现业务需求,更加合适。
为什么呢?
因为如果sql语句中包含了in关键字,则它会优先执行in里面的子查询语句,然后再执行in外面的语句。如果in里面的数据量很少,作为条件查询速度更快。
而如果sql语句中包含了exists关键字,它优先执行exists左边的语句(即主查询语句)。然后把它作为条件,去跟右边的语句匹配。如果匹配上,则可以查询出数据。如果匹配不上,数据就被过滤掉了。
这个需求中,order表有10000条数据,而user表有100条数据。order表是大表,user表是小表。如果order表在左边,则用in关键字性能更好。
总结一下:
不管是用in,还是exists关键字,其核心思想都是用小表驱动大表。
如果你有一批数据经过业务处理之后,需要插入数据,该怎么办?
反例:
for(Order order: list){
orderMapper.insert(order):
}在循环中逐条插入数据。
insert into order(id,code,user_id)
values(123,'001',100);该操作需要多次请求数据库,才能完成这批数据的插入。
但众所周知,我们在代码中,每次远程请求数据库,是会消耗一定性能的。而如果我们的代码需要请求多次数据库,才能完成本次业务功能,势必会消耗更多的性能。
那么如何优化呢?
正例:
orderMapper.insertBatch(list):提供一个批量插入数据的方法。
insert into order(id,code,user_id)
values(123,'001',100),(124,'002',100),(125,'003',101);这样只需要远程请求一次数据库,sql性能会得到提升,数据量越多,提升越大。
但需要注意的是,不建议一次批量操作太多的数据,如果数据太多数据库响应也会很慢。批量操作需要把握一个度,建议每批数据尽量控制在500以内。如果数据多于500,则分多批次处理。
最近我建了新的技术交流群,打算将它打造成高质量的活跃群,欢迎小伙伴们加入。
我以往的技术群里技术氛围非常不错,大佬很多。
有时候,我们需要查询某些数据中的第一条,比如:查询某个用户下的第一个订单,想看看他第一次的首单时间。
反例:
select id, create_date
from order
where user_id=123
order by create_date asc;
根据用户id查询订单,按下单时间排序,先查出该用户所有的订单数据,得到一个订单集合。然后在代码中,获取第一个元素的数据,即首单的数据,就能获取首单时间。
List<Order> list=orderMapper.getOrderList();
Order order=list.get(0);
虽说这种做法在功能上没有问题,但它的效率非常不高,需要先查询出所有的数据,有点浪费资源。
那么,如何优化呢?
正例:
select id, create_date
from order
where user_id=123
order by create_date asc
limit 1;
使用limit 1,只返回该用户下单时间最小的那一条数据即可。
此外,在删除或者修改数据时,为了防止误操作,导致删除或修改了不相干的数据,也可以在sql语句最后加上limit。
例如:
update order set status=0,edit_time=now(3)
where id>=100 and id<200 limit 100;
这样即使误操作,比如把id搞错了,也不会对太多的数据造成影响。
对于批量查询接口,我们通常会使用in关键字过滤出数据。比如:想通过指定的一些id,批量查询出用户信息。
sql语句如下:
select id,name from category
where id in (1,2,3...100000000);
如果我们不做任何限制,该查询语句一次性可能会查询出非常多的数据,很容易导致接口超时。
这时该怎么办呢?
select id,name from category
where id in (1,2,3...100)
limit 500;
可以在sql中对数据用limit做限制。
不过我们更多的是要在业务代码中加限制,伪代码如下:
public List<Category> getCategory(List<Long> ids){
if(CollectionUtils.isEmpty(ids)){
return null;
}
if(ids.size() > 500){
throw new BusinessException("一次最多允许查询500条记录")
}
return mapper.getCategoryList(ids);
}
还有一个方案就是:如果ids超过500条记录,可以分批用多线程去查询数据。每批只查500条记录,最后把查询到的数据汇总到一起返回。
不过这只是一个临时方案,不适合于ids实在太多的场景。因为ids太多,即使能快速查出数据,但如果返回的数据量太大了,网络传输也是非常消耗性能的,接口性能始终好不到哪里去。
有时候,我们需要通过远程接口查询数据,然后同步到另外一个数据库。
反例:
select * from user;
如果直接获取所有的数据,然后同步过去。这样虽说非常方便,但是带来了一个非常大的问题,就是如果数据很多的话,查询性能会非常差。
这时该怎么办呢?
正例:
select * from user
where id>#{lastId}and create_time >=#{lastCreateTime}
limit 100;
按id和时间升序,每次只同步一批数据,这一批数据只有100条记录。每次同步完成之后,保存这100条数据中最大的id和时间,给同步下一批数据的时候用。
通过这种增量查询的方式,能够提升单次查询的效率。
有时候,列表页在查询数据时,为了避免一次性返回过多的数据影响接口性能,我们一般会对查询接口做分页处理。
在mysql中分页一般用的limit关键字:
select id,name,age
from user limit 10,20;
如果表中数据量少,用limit关键字做分页,没啥问题。但如果表中数据量很多,用它就会出现性能问题。
比如现在分页参数变成了:
select id,name,age
from user limit 1000000,20;
mysql会查到1000020条数据,然后丢弃前面的1000000条,只查后面的20条数据,这个是非常浪费资源的。
那么,这种海量数据该怎么分页呢?
优化sql:
select id,name,age
from user where id > 1000000 limit 20;
先找到上次分页最大的id,然后利用id上的索引查询。不过该方案,要求id是连续的,并且有序的。
还能使用between优化分页。
select id,name,age
from user where id between 1000000 and 1000020;
需要注意的是between要在唯一索引上分页,不然会出现每页大小不一致的问题。
最近就业形式比较困难,为了感谢各位小伙伴对苏三一直以来的支持,我特地创建了一些工作内推群, 看看能不能帮助到大家。
你可以在群里发布招聘信息,也可以内推工作,也可以在群里投递简历找工作,也可以在群里交流面试或者工作的话题。
mysql中如果需要从两张以上的表中查询出数据的话,一般有两种实现方式:子查询 和 连接查询。
子查询的例子如下:
select * from order
where user_id in (select id from user where status=1)
子查询语句可以通过in关键字实现,一个查询语句的条件落在另一个select语句的查询结果中。程序先运行在嵌套在最内层的语句,再运行外层的语句。
子查询语句的优点是简单,结构化,如果涉及的表数量不多的话。
但缺点是mysql执行子查询时,需要创建临时表,查询完毕后,需要再删除这些临时表,有一些额外的性能消耗。
这时可以改成连接查询。具体例子如下:
select o.* from order o
inner join user u on o.user_id=u.id
where u.status=1
根据阿里巴巴开发者手册的规定,join表的数量不应该超过3个。
反例:
select a.name,b.name.c.name,d.name
from a
inner join b on a.id=b.a_id
inner join c on c.b_id=b.id
inner join d on d.c_id=c.id
inner join e on e.d_id=d.id
inner join f on f.e_id=e.id
inner join g on g.f_id=f.id
如果join太多,mysql在选择索引的时候会非常复杂,很容易选错索引。
并且如果没有命中中,nested loop join 就是分别从两个表读一行数据进行两两对比,复杂度是 n^2。
所以我们应该尽量控制join表的数量。
正例:
select a.name,b.name.c.name,a.d_name
from a
inner join b on a.id=b.a_id
inner join c on c.b_id=b.id
如果实现业务场景中需要查询出另外几张表中的数据,可以在a、b、c表中冗余专门的字段,比如:在表a中冗余d_name字段,保存需要查询出的数据。
不过我之前也见过有些ERP系统,并发量不大,但业务比较复杂,需要join十几张表才能查询出数据。
所以join表的数量要根据系统的实际情况决定,不能一概而论,尽量越少越好。
我们在涉及到多张表联合查询的时候,一般会使用join关键字。
而join使用最多的是left join和inner join。
使用inner join的示例如下:
select o.id,o.code,u.name
from order o
inner join user u on o.user_id=u.id
where u.status=1;
如果两张表使用inner join关联,mysql会自动选择两张表中的小表,去驱动大表,所以性能上不会有太大的问题。
使用left join的示例如下:
select o.id,o.code,u.name
from order o
left join user u on o.user_id=u.id
where u.status=1;
如果两张表使用left join关联,mysql会默认用left join关键字左边的表,去驱动它右边的表。如果左边的表数据很多时,就会出现性能问题。
要特别注意的是在用left join关联查询时,左边要用小表,右边可以用大表。如果能用inner join的地方,尽量少用left join。
众所周知,索引能够显著的提升查询sql的性能,但索引数量并非越多越好。
因为表中新增数据时,需要同时为它创建索引,而索引是需要额外的存储空间的,而且还会有一定的性能消耗。
阿里巴巴的开发者手册中规定,单表的索引数量应该尽量控制在5个以内,并且单个索引中的字段数不超过5个。
mysql使用的B+树的结构来保存索引的,在insert、update和delete操作时,需要更新B+树索引。如果索引过多,会消耗很多额外的性能。
那么,问题来了,如果表中的索引太多,超过了5个该怎么办?
这个问题要辩证的看,如果你的系统并发量不高,表中的数据量也不多,其实超过5个也可以,只要不要超过太多就行。
但对于一些高并发的系统,请务必遵守单表索引数量不要超过5的限制。
那么,高并发系统如何优化索引数量?
能够建联合索引,就别建单个索引,可以删除无用的单个索引。
将部分查询功能迁移到其他类型的数据库中,比如:Elastic Seach、HBase等,在业务表中只需要建几个关键索引即可。
char表示固定字符串类型,该类型的字段存储空间的固定的,会浪费存储空间。
alter table order
add column code char(20) NOT NULL;varchar表示变长字符串类型,该类型的字段存储空间会根据实际数据的长度调整,不会浪费存储空间。
alter table order
add column code varchar(20) NOT NULL;如果是长度固定的字段,比如用户手机号,一般都是11位的,可以定义成char类型,长度是11字节。
但如果是企业名称字段,假如定义成char类型,就有问题了。
如果长度定义得太长,比如定义成了200字节,而实际企业长度只有50字节,则会浪费150字节的存储空间。
如果长度定义得太短,比如定义成了50字节,但实际企业名称有100字节,就会存储不下,而抛出异常。
所以建议将企业名称改成varchar类型,变长字段存储空间小,可以节省存储空间,而且对于查询来说,在一个相对较小的字段内搜索效率显然要高些。
我们在选择字段类型时,应该遵循这样的原则:
还有很多原则,这里就不一一列举了。
我们有很多业务场景需要使用group by关键字,它主要的功能是去重和分组。
通常它会跟having一起配合使用,表示分组后再根据一定的条件过滤数据。
反例:
select user_id,user_name from order
group by user_id
having user_id <=200;
这种写法性能不好,它先把所有的订单根据用户id分组之后,再去过滤用户id大于等于200的用户。
分组是一个相对耗时的操作,为什么我们不先缩小数据的范围之后,再分组呢?
正例:
select user_id,user_name from order
where user_id <=200
group by user_id使用where条件在分组前,就把多余的数据过滤掉了,这样分组时效率就会更高一些。
其实这是一种思路,不仅限于group by的优化。我们的sql语句在做一些耗时的操作之前,应尽可能缩小数据范围,这样能提升sql整体的性能。
sql优化当中,有一个非常重要的内容就是:索引优化。
很多时候sql语句,走了索引,和没有走索引,执行效率差别很大。所以索引优化被作为sql优化的首选。
索引优化的第一步是:检查sql语句有没有走索引。
那么,如何查看sql走了索引没?
可以使用explain命令,查看mysql的执行计划。
例如:
explain select * from `order` where code='002';结果:

通过这几列可以判断索引使用情况,执行计划包含列的含义如下图所示:
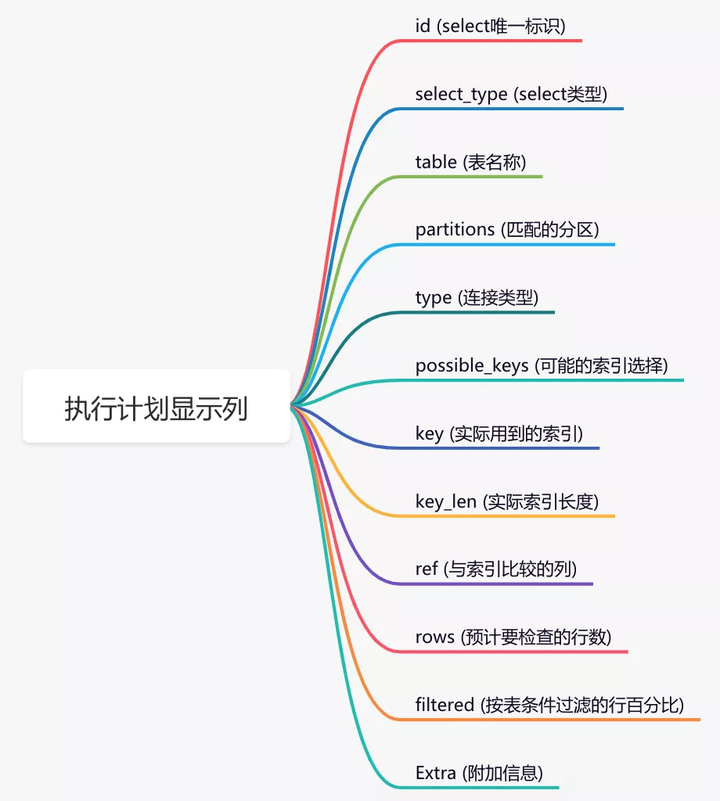
如果你想进一步了解explain的详细用法,可以看看我的另一篇文章《explain | 索引优化的这把绝世好剑,你真的会用吗?》
说实话,sql语句没有走索引,排除没有建索引之外,最大的可能性是索引失效了。
下面说说索引失效的常见原因:

如果不是上面的这些原因,则需要再进一步排查一下其他原因。
此外,你有没有遇到过这样一种情况:明明是同一条sql,只有入参不同而已。有的时候走的索引a,有的时候却走的索引b?
没错,有时候mysql会选错索引。
必要时可以使用force index来强制查询sql走某个索引。
至于为什么mysql会选错索引,后面有专门的文章介绍的,这里先留点悬念。
最近我建了新的技术交流群,打算将它打造成高质量的活跃群,欢迎小伙伴们加入。
我以往的技术群里技术氛围非常不错,大佬很多。
如果这篇文章对您有所帮助,或者有所启发的话,帮忙扫描下发二维码关注一下,您的支持是我坚持写作最大的动力。
求一键三连:点赞、转发、在看。
最近无意间获得一份阿里大佬写的刷题笔记,一下子打通了我的任督二脉,进大厂原来没那么难。
链接:https://pan.baidu.com/s/1UECE5yuaoTTRpJfi5LU5TQ 密码:bhbe
不会有人刷到这里还想白嫖吧?点赞对我真的非常重要!在线求赞。加个关注我会非常感激! @苏三说技术
此外,本文GitHubhttps://github.com/dvsusan/susanSayJava已经收录,有大厂面试完整考点,工作经验分享,欢迎Star。
Copyright © 2002-2021 天辰-天辰注册伸缩门卷闸门销售站 备案号:


020-88888888















